
Spend Analytics
What happens to my spend data after it’s sent to Xeeva for Spend Analytics?
As a new Xeeva Spend Analytics customer is being onboarded, we often get asked “what happens to my spend data?” After the hard work of collecting all the details has been done and a complete data set has been handed over to the Xeeva team for processing, it’s common for you to wonder what exactly we’re doing with your data. You may hear that it could take several weeks to organize, cleanse, and categorize your spend data before you get to see it working in the Xeeva Spend Analytics platform. So, what’s going on during the four to six weeks before you can see your spend data presented?
Getting your spend data ready
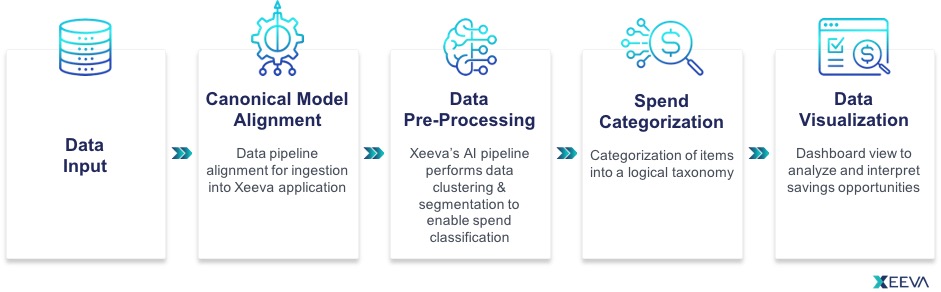
Once we receive your spend data files, our first step is to take all the data provided, including the transactional details, and structure it into an ingestible format for our AI technology, what we call the XVA Platform. This one-time process can take some time to get data aligned and the initial mapping “jobs” built. Doing so will establish the foundation for ingesting all monthly or quarterly data sets submitted in the future. At Xeeva, we rely heavily on the consistency of how the data is submitted to ensure this process remains efficient and repeatable. After the data is aligned, we perform what we call “data pre-processing”. This is our patented machine learning algorithms’ (aka AI’s) first real view of your data.
There are two key jobs we run prior to processing your data:
- Quality Assessment: The initial quality of your data is assessed to establish the modeling your data will require.
- Data Pre-Processing: We think of as training our AI to your specific data. Key elements such as item description, item number, and supplier name are first segmented then clustered to identify a highly probable set of reference points for the automated classification process to read from in order to produce confident returns.
Spend categorization & classification
Now that our AI has become familiar with your data, the next step is to categorize each transaction. Using a blend of standard structures like NAICS and UNSPSC along with our experience through our extensive item and supplier reference databases, we begin to place your spend data into our multi-level taxonomy. This process can often take the most time.
After our AI technology has performed the first round of classification, we manually review each item that produced a rating lower than “high confidence”. Depending on the overall quality of the item details, this can take a few days to complete. Our highly trained context team pours over the details to ensure that we have considered all the information to provide an accurate classification of each transaction. The final output ensures you have the deepest item-level categorization structure possible. We apply a three-level structure: starting at category type (i.e. MRO, services, capital, IT), category, and down to a sub-category level (i.e. hand protection, specific labor types for services, and hundreds of other sub-categories).
Related: What you need to know about Xeeva’s product release upgrades (FAQs)
Once the classification has been completed, the focus shifts to organization. This is where the transactional details are married with any master data files (i.e. location master, payment term master, etc.), all assumed calculations are made, and the details are organized into the proper format.
Finally, the formatted data is loaded into your Spend Analytics application and the insights and dashboards are rendered. Our experienced professionals then review the application for accuracy and alignment to key spend areas such as spend by month, location, and supplier.
Xeeva’s AI-driven processes can take your raw data, classify it at an item level, and present it across numerous angles like data quality and savings opportunities – arming your procurement team with actionable information in just a few clicks.
Recurring data refreshes
For incremental updates, the process is very similar. The main advantage is that our AI technology has learned and will continue to learn as it receives more data and starts to better understand it. The steps for these updates are still in place and must be performed before load, but by getting standard spend data files and our AI learnings, this timeline is more efficient and can be visible in the application in about half the time of the initial processing – within about three weeks or less.
We hope this blog helps you to better understand the many steps your data undergoes between you submitting your raw data and you seeing your data, both enriched and classified by our proprietary AI technology, in your Xeeva Spend Analytics dashboards. If you have additional questions, please reach out to your customer success manager.